Demystifying the math and implementation of Convolutions: Part III.
In this part, we will discuss how to implement convolutions over 3D matrices, such as RGB images. We will also discuss how to optimize the code using im2col and vectorization.
Convolution over Volume
Convolution over volume refers to 3D input matrices, such as RGB Images. While I will not be implementing them here (not in this post at least), they are essentially easy to implement if you are able to model them as matrices and vectors. However, I will explain the process of modeling such high dimensional data.
First thing, we have seen convolutions over 2D matrices, which can also treated as 3D matrices with a depth of 1. Starting from there, let’s remodel what we have done so far in terms of 3D matrices. Let M be a 3D image, and the shape of out matrix is rowscolumnsdepth, as depicted in figure 1.
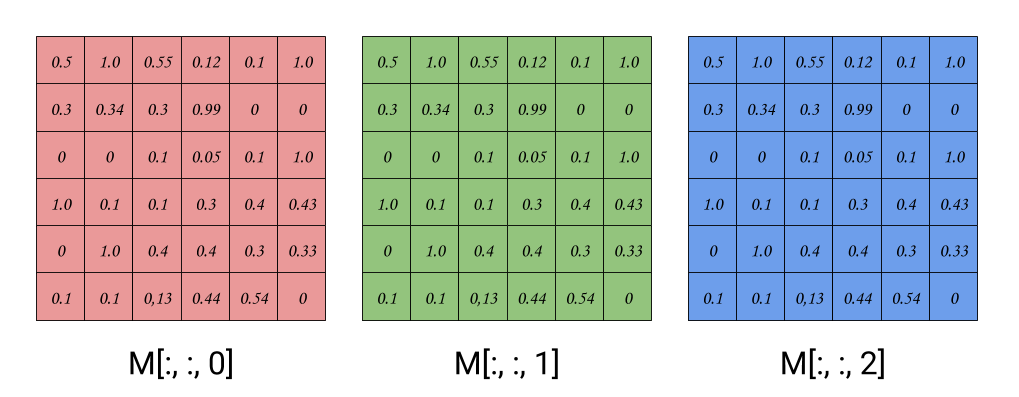
Given an input image M: mnd and filter K: m’*n’*d’ the convolution operation is only valid if and only if k = k’, thus we will refer to the depth of the input matrix and the filter as k.
The most important things to remember are:
- Convolution of any kind of matrix over a single filter, results in a 2D Image.
- Matrix and Filter must have the same rank (i.e Number of dimensions) and the depth must be the same
- The fact that I am going to assume a stride of 1 for the rest of this tutorial
Now, with that in mind, let’s see how our convolution goes:
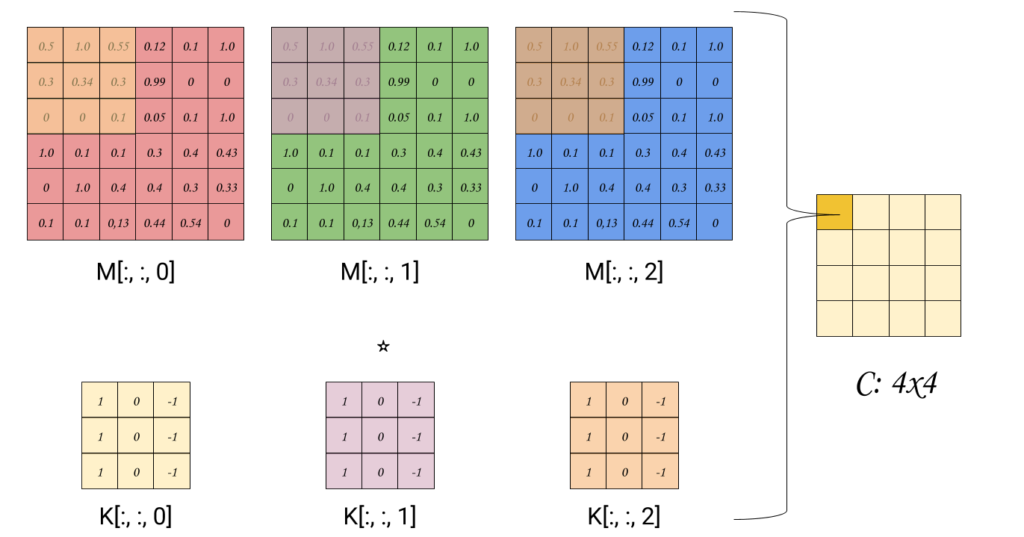
Now, we wont be starting from scratch. Let’s recall our good ol’ Convolution formula over standard Matrices
.png)
We transformed this problem into matrix dot product using im2col, as depicted in figure 3.
.png) Convolution over volume is the pretty much the same, we split the image and filters by depth (channels), perform standard convolution of each image by its respective filters, and the final convolution value is the sum of each single convolution.
Convolution over volume is the pretty much the same, we split the image and filters by depth (channels), perform standard convolution of each image by its respective filters, and the final convolution value is the sum of each single convolution.
.png)
Let’s see if we can straight optimize this code using im2col. One thing we can do is, when we generate the column matrix M’, is to apply im2col to every channel, and concatenate all columns together as a single column into our new matrix as in the images, below thus the final output shape of M’ is (Cx*Cy, m’*n’*d) where Cx and Cy are the convolution output shape calculated using standard output formula from Part I, and m’, n’, d are the dimensions of the filter
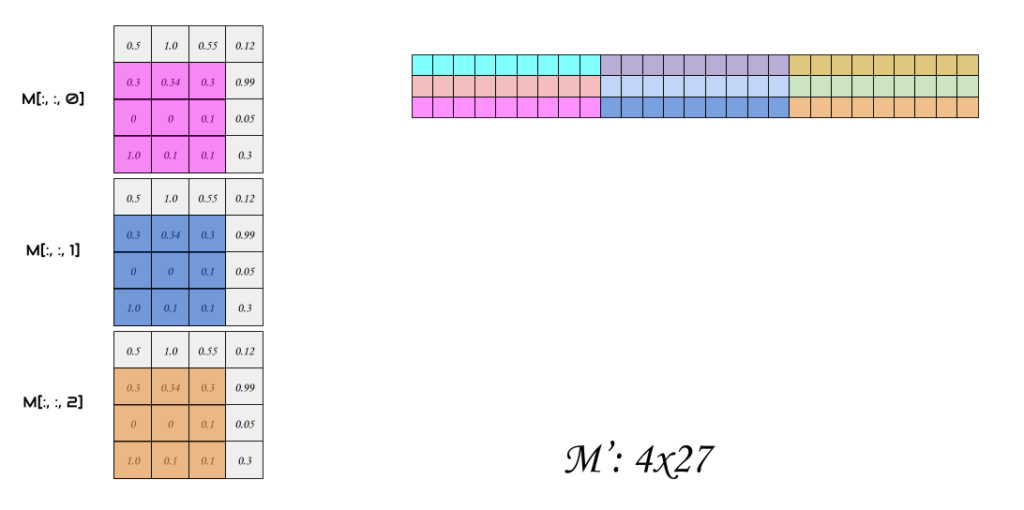
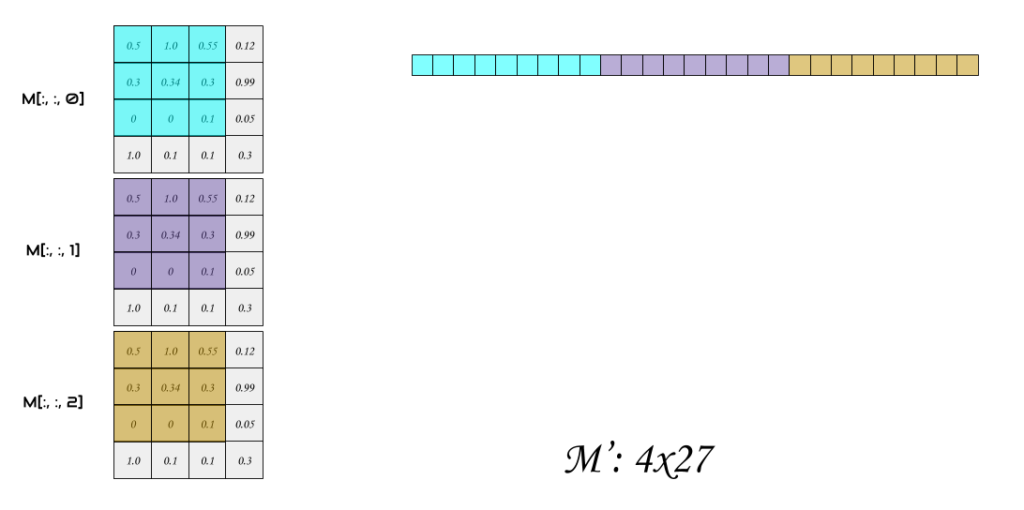
Next step, is the flatten the Filter, we do the same thing, we flatten the filter into a row matrix, (mnd,1) as in figure 5.
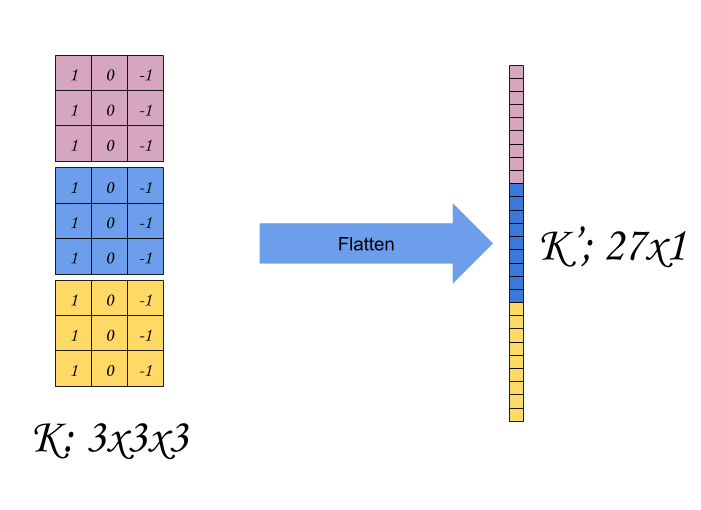
Once we do this, our convolution is easily expressed as DOT product of M’ dot K’.
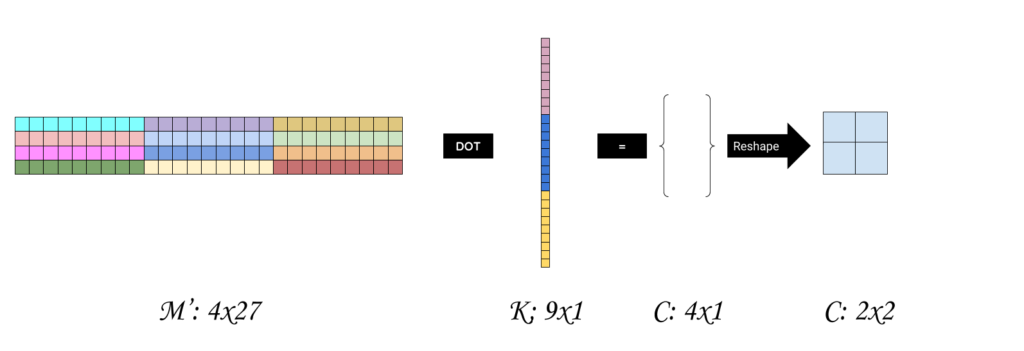
If we wanted to add more filters, we simple add them as columns to the flattened filter! Only when reshaping the output matrix C, we consider the number of filters as the depth of the convolution.
SHOW ME THE CODE
Alright, the following code is based on im2col from previous part, extends it to 3 dimensional inputs and filters. It only processes, however one filter. Your task in to fork it and make it work with n filters.
In case you doubt my math and coding skills, here is a Keras version that exactly the same thing:
Conclusion
With this, I have finished almost everything related to convolution operator. A couple of details were not mentioned which I will discuss in another part (or a separate post) are
- Zero padding: A technique to increase the output size of a convolution
- Activation Functions: Transform convolutions into signals/energies
- Max Pooling: Reduce the shape of an input to reduce computation time and preserve the most essential/important information in the image/convolution.
I hope this series of posts have been informative to you as it has been pleasant for me to write.
Articles written in this blog are my own opinions and do not reflect the views of my employer. Content on this website is original unless mentioned otherwise. Original content is licensed under a CC BY 4.0 Deed. Some of the content might have been preprocessed by AI for clarity and articulation.