Have you heard of Bloom Filters?
Bloom filter, a fancy name for a a very simple algorithm. We will have a look at bloom filters, how they work, and how to use them. Also, look at an efficient C implementation of bloom filter.
What is a bloom filter?
I like to start with simple definition, rather than a very formal one. A bloom filter is a very similar approach to indexing, where you first have to insert data into a data structure, which in the context of a bloom filter, is a filter (duh!) and later on query it to see if a given value exists or not. That’s what a bloom filter is at the end of day. But what makes it special?
Let’s analyze how bloom filters are defined on wikipedia:
A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set. False positive matches are possible, but false negatives are not – in other words, a query returns either “possibly in set” or “definitely not in set”.
This definition defines key features of bloom filters:
- Probabilistic: Meaning that the result is not 100% accurate. There is a chance that the result is wrong.
- Space-efficient: Bloom filters are very space efficient. They can store a lot of data in a very small space.
- False positive: Bloom filters can return false positives. Meaning that the filter might say that a value exists in the filter, while it doesn’t.
- False negative: Bloom filters can never return false negatives. Meaning that the filter will never say that a value doesn’t exist in the filter, while it does.
False what?
False positive and false negative are two terms that are used in statistics. Let’s say you are searching the web for a specific term. The engine will look for the term in its index and return the results.
- true positive: when the search engine returns a relevant item (relevant, classified as relevant by the search engine).
- false positive: when the search engine returns an irrelevant item (irrelevant, classified as relevant by the search engine).
- false negative: when the search engine doesn’t return a relevant item (relevant, classified as irrelevant by the search engine).
- true negative: when the search engine doesn’t return an irrelevant item (irrelevant, classified as irrelevant by the search engine).
How does bloom filter work?
Bloom filters are very simple, once you understand the concept. A bloom filter needs some requirements:
- A bit array: A bit array is an array of bits. Each bit can be either 0 or 1. The size of the array is determined by the number of items that you want to store in the filter.
- A number of hash functions: A hash function is a function that takes a value and returns a number.
- A set of values: The values that you want to store in the filter.
Let’s write some pseudo code to see how a bloom filter works:
step1: empty bit array
filter = [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ]
data1 = "hi"
data2 = "hello"
data3 = "hey"
query_data1 = "hi"
query_data2 = "hii"
For simplicity, we will need use a proper hash function. Instead, we will persume the hash function output so we can visualize the process better.
Let’s define our function hash as follows:
hash("hi") = [ 1, 0, 0, 1, 0, 1, 0, 0, 1, 0 ]
hash("hello") = [ 0, 1, 0, 1, 0, 1, 0, 0, 1, 0 ]
hash("hey") = [ 0, 0, 1, 1, 0, 1, 0, 0, 1, 0 ]
Now that we know the hash of each value, we can insert them into the filter. In practice, you can use a number as filter, such as an int, to set the hash, we have the insert the hot bits in the hash into the filter. Let’s do that:
| action | hash value to insert | new filter value |
|---|---|---|
| init filter | [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ] | [ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ] |
| insert “hi” | [ 1, 0, 0, 1, 0, 1, 0, 0, 1, 0 ] | [ 1, 0, 0, 1, 0, 1, 0, 0, 1, 0 ] |
| insert “hello” | [ 0, 1, 0, 1, 0, 1, 0, 0, 1, 0 ] | [ 1, 1, 0, 1, 0, 1, 0, 0, 1, 0 ] |
| insert “hey” | [ 0, 0, 1, 1, 0, 1, 0, 0, 1, 0 ] | [ 1, 1, 1, 1, 0, 1, 0, 0, 1, 0 ] |
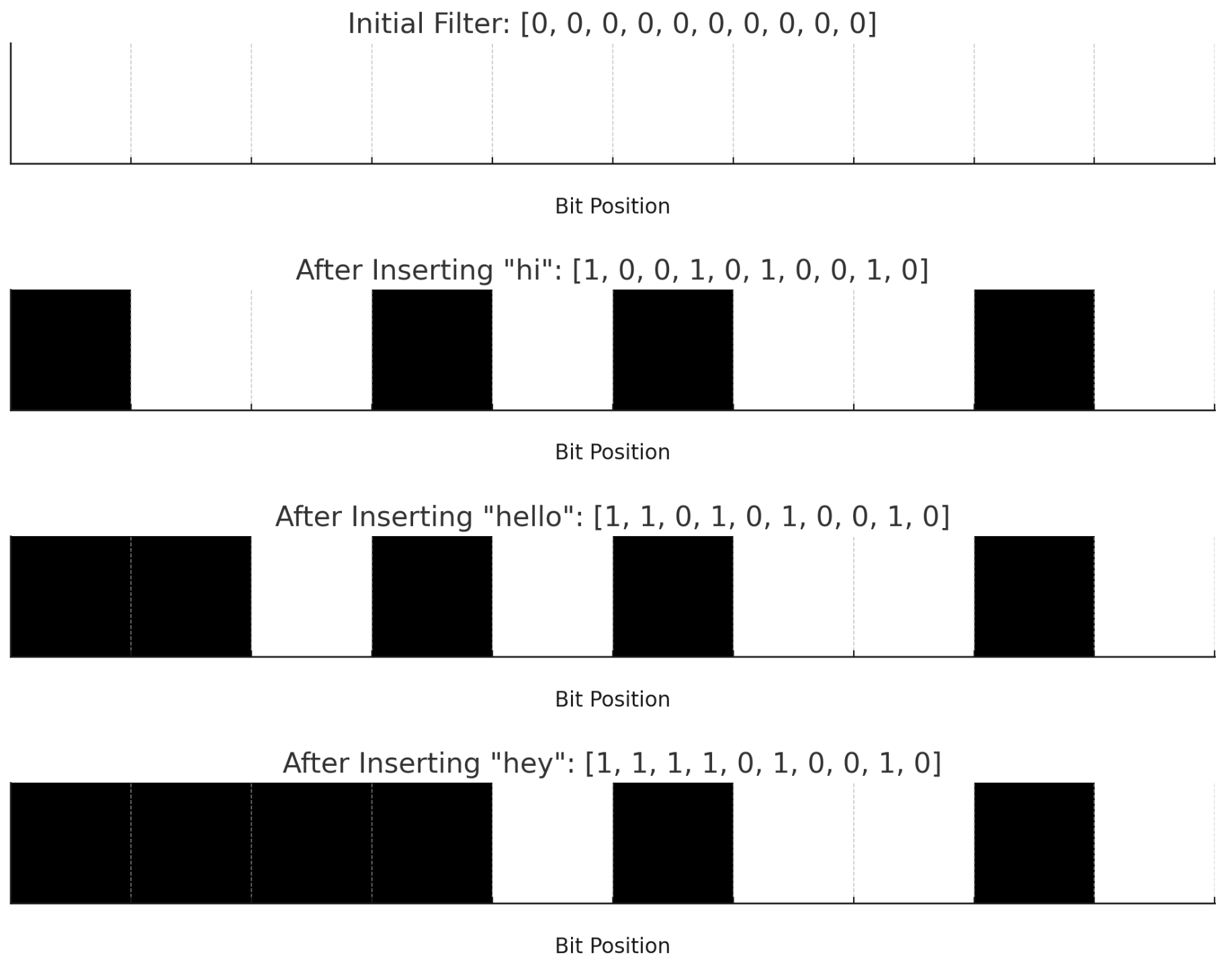 Figure1: Bloom filter flow
Figure1: Bloom filter flow
Now that we have inserted the values into the filter, we can query the filter to see if a value exists or not. Checking if a result exist or not, is done by checking the value of the bits in the filter. If all the bits are set, then the value exists in the filter. If one of the bits is not set, then the value doesn’t exist in the filter. Let’s see how that works:
| action | hash value to query | filter value | result |
|---|---|---|---|
| query “hi” | [ 1, 0, 0, 1, 0, 1, 0, 0, 1, 0 ] | [ 1, 1, 1, 1, 0, 1, 0, 0, 1, 0 ] | true |
| query “hii” | [ 1, 0, 0, 1, 0, 1, 0, 0, 1, 1 ] | [ 1, 1, 1, 1, 0, 1, 0, 0, 1, 0 ] | false |
As you can see, the filter returned true for the first query, which means that the value exists in the filter. However, the second query returned false, which means that the value doesn’t exist in the filter. Let’s see why it is possible to have false positives in bloom filters.
Let’s querty for a new value, that we didn’t insert into the filter:
query_data3 = "sup!"
hash("sup!") = [ 0, 0, 1, 0, 0, 0, 0, 0, 1, 0 ]
Now let’s query the filter for the value sup!:
| action | hash value to query | filter value | result |
|---|---|---|---|
| query “sup!” | [ 0, 0, 1, 0, 0, 0, 0, 0, 1, 0 ] | [ 1, 1, 1, 1, 0, 1, 0, 0, 1, 0 ] | true |
Now we have a false positive. The filter returned true for a value that doesn’t exist in the filter.
 Figure2: Querying for a value, query bits are in red.
Figure2: Querying for a value, query bits are in red.
Here is another query for “what’s up?”:
hash("what's up") = [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1]
| action | hash value to query | filter value | result |
|---|---|---|---|
| query “what’s up?” | [ 0, 0, 0, 0, 0, 0, 0, 1, 0, 1] | [ 1, 1, 1, 1, 0, 1, 0, 0, 1, 0 ] | false |
 Figure2: Querying for a value, query bits are in red.
Figure2: Querying for a value, query bits are in red.
Let’s review what explained earlier now:
- Probabilistic Model: It looks at the result of all the additions of the hashes in the set, rather than look up each element. It doesn’t store history or any of the sort.
- Can return false positives: because a hash of a non-existing item, can overlap with the sum of hashes of multiple other existing items.
- Cannot return false negatives: because if an item does exist in the filter, then all the bits in the filter will be set.
- Space efficient: because it only stores the bits in the filter, rather than the actual items.
Why are they even useful?
First, you must have a problem where false positives are acceptable. Let’s take a look an example, fraud detection. When a user pays for something online, the bank can check if the transaction is fraudulent or not. False positive in this scenario are acceptable as long as they are not too frequent. Because fraud detection doesn’t actually detect a fraudulent operation, but rather a potentially fraudulent transaction. One way the banking platform does this is:
- Query for the user location
- Check if his location is in the filter
- If it is, then the transaction is most likely legit
- If it is not, then the transaction suspicious, and maybe it will ask for 2FA.
And yes, the bank can just store his location in a database and query it there but to the point is, think of the performance impact of running a query on an array vs performing a couple of bit manipulation on integers.
Additionally, bloom filters gives you some control over the false positive rate. You can control the false positive rate by changing the number of hash functions and the size of the filter. The more hash functions you have, the less false positives you will have. The larger the filter, the less false positives you will have. However, the larger the filter, the more space it will take.
Also, as I mentioned, it is fast! What makes it fast is that inserting and querying the filter is just a matter of setting and checking bits. In C, this is as simple as filter |= hash_value and filter & hash_value == hash_value. Such bit manipulation insturctions are extremely optimized on modern CPUs. However hash functions performance also plays a role in the performance of bloom filters! Hence, they must be picked wisely.
Let’s review the bloom filter parameters and how they affect the performance of the filter:
- Number of hash functions: The more hash functions you have, the less false positives you will have. Also having too many hashes, will increase the time it takes to insert and query the filter.
- Size of the filter: The larger the filter, the less false positives you will have. Also having a larger filter will increase the time it takes to insert and query the filter.
- Hash functions: The hash functions themselves also play a role in the performance of the filter. The faster the hash function, the faster the filter will be. However, the hash function must be good enough to avoid collisions. A balance between speed and uniformity in a hash function is the best choice.
- Number of items: The more items you have, the more space you will need to store them. However, the more items you have, the more likely you will have false positives.
There few considerations to take into account when using bloom filters:
- Fixed size: Once you create a bloom filter, you cannot change its size. You will have to create a new filter with a different size.
- No data removal: You cannot remove items from a bloom filter. Once you insert an item, it will stay there forever. You can only create a new filter and insert the items you want to keep.
How do I pick the parameters?
A lot of studies has been performed on bloom filters. There are a lot of papers that discuss the parameters of bloom filters. However, there is no one-size-fits-all solution. You will have to pick the parameters based on your use case.
Since this is not a data science post, I will spare you the mathematical formulares and the proofs of how much space you need to store a certain number of items with a certain false positive rate. I will give you one better:
https://hur.st/bloomfilter/, this tool provide you with a simple interface to calculate the parameters of a bloom filter. Think for example of the maximum amout of data you want to store in the filter, say 1m items, and the false positive rate you want, say 1%, and the number of hash functions you plan to use. The tool will give you the size of the filter you need to use.
n = 1000000
p = 0.01 (1 in 100)
m = 12364167 (1.47MiB)
k = 3
The tool will also provide you with graphs, to help you choose the parameters.
Bloom filter in practice
The bloom filter is easy to implement. You can implement it in any language you want. However since it is optimized for speed, you should implement it in a language that is fast. I would recommend C or C++. Also the language needs to support bit manipulation.
Now instead of from-scarch implementation, I want to review an existing code:
https://github.com/jvirkki/libbloom
This is a C implementation of a bloom filter. Let’s have a look at how its API, the initialization function looks as follows:
int bloom_init2(struct bloom * bloom, unsigned int entries, double error);| parameter | description |
|---|---|
| bloom | The bloom filter to initialize |
| entries | The expected number of items to be stored in the filter |
| error | The desired false positive rate |
int bloom_add(struct bloom * bloom, const void * buffer, int len);| parameter | description |
|---|---|
| bloom | The bloom filter to add the item to |
| buffer | The item to add to the filter |
| len | The length of the item |
It also returns:
- 0: if the item was newly added
- 1: if the item already exists in the filter (could be a FP)
- -1: filter was not initialized (error)
int bloom_check(struct bloom * bloom, const void * buffer, int len);| parameter | description |
|---|---|
| bloom | The bloom filter to check the item in |
| buffer | The item to check in the filter |
| len | The length of the item |
Also returns:
- 0: if the item doesn’t exist in the filter
- 1: if the item exists in the filter (could be a FP too)
- -1: filter was not initialized (error)
Now that we have defined the API, you can start using the library at it is, but we are here to look deeper! Let’s see how it adds items into the filter:
// as per last commit `5df5042`
// also this code is part of libbloom,
// licensed under as specified in the LICENSE file of the project
static int bloom_check_add(struct bloom * bloom,
const void * buffer, int len, int add)
{
if (bloom->ready == 0) {
printf("bloom at %p not initialized!\n", (void *)bloom);
return -1;
}
unsigned char hits = 0;
unsigned int a = murmurhash2(buffer, len, 0x9747b28c);
unsigned int b = murmurhash2(buffer, len, a);
unsigned long int x;
unsigned long int i;
for (i = 0; i < bloom->hashes; i++) {
x = (a + b*i) % bloom->bits;
if (test_bit_set_bit(bloom->bf, x, add)) {
hits++;
} else if (!add) {
// Don't care about the presence of all the bits. Just our own.
return 0;
}
}
if (hits == bloom->hashes) {
return 1; // 1 == element already in (or collision)
}
return 0;
}Now this is where it gets interesting! We have been diving into theory a lot, but in practice, we can squeeze a lot of performance out of bloom filters. Let’s see how this code works:
First, bloom->hashes is a char. It simply contains the number of hashes we have to use.
a contains the first hash value, which is computed on a fixed seed of 0x9747b28c. b contains the second hash value, which is computed on a seed of a. Essentially, it is using the output of one hash, as the seed for the second, to generate diverse hash values, while using the same hash function.
Now on every iteration of the loop, it computes a + b*i, which is the hash value of the item. This value will change depending on the current hash index, since it is multiplied by i. This is how it generates multiple hash values from the same hash function. Finally, the mod operations guarentees that the hash value is within the range of the filter size.
One final note: 0x9747b28c might appear arbitrary, it might be, but it is also possible for this number to have been picked after some testing. The seed of the hash function can affect the distribution of the hash values.
Conclusion
Instead of writing a conclusion for the reader, I am writing one for myself. Originally, I wanted to write about developing bloom filters from scratch, until I have discovered how they are actually implemented for maximum performance. My conclusion is that, when implementing algorithms, do not just implement based on the theory. Think out of the box and ask yourself, can this be done better? This is only relevant if you want to push the limits of performance. If you are just coding for learning, I suppose you don’t need as much optimizations.
Articles written in this blog are my own opinions and do not reflect the views of my employer. Content on this website is original unless mentioned otherwise. Original content is licensed under a CC BY 4.0 Deed. Some of the content might have been preprocessed by AI for clarity and articulation.